
ماشین لرنینگ چیست؟ - معرفی Machine Learning

امروزه دیگه همه تقریبا حداقل یک بار اسم "یادگیری ماشین" یا به اصطلاح "Machine Learning" را شنیده اند.
و از ابزار هایی استفاده میکنند که در آن ها از ماشین لرنینگ استفاده شده است.
مثل ChatGPT, Copilot, Gemini و...
اما یادگیری ماشین به چه معناست؟
ماشین لرنینگ یا یادگیری ماشین چیست؟
در واقع، ماشین لرنینگ با توجه به داده هایی که از قبل با آن آموزش دیده، میتواند به وظایف جدیدی که از قبل با آن روبرو نشده پاسخ مناسب دهد.
برای مثال ChatGPT را در نظر بگیرید.
بنظر شما جواب تمام سوال هایی که کاربران از ChatGPT میپرسند قبلا به آن داده شده؟ قطعا نه!
بلکه با توجه به آموزش هایی که قبلا با حجم بسیار زیادی از داده ها دیده میتواند جواب اکثر سوالات کاربران را بدهد.
تاریخچه ماشین لرنینگ

احتمالا تعداد زیادی از افرادی که این مقاله را میخوانند فکر میکنند ماشین لرنینگ در چند سال گذشته توسعه داده شده اما اینطور نیست.
مفهوم ماشین لرنینگ از چندین دهه پیش وجود داشته، اما با پیشرفت تکنولوژی و افزایش توان پردازشی کامپیوترها، این حوزه در چند سال اخیر رشد بسیار زیادی داشته است.
بطوری که اکثر شرکت های بزرگ دنیا مثال اپل، گوگل، مایکروسافت و سامسونگ سرمایه گذاری زیادی روی این بخش کرده اند.
میتوان اولین فعالیت ها در این حوزه را به آلن تورینگ (Alan Turing) نسبت داد.او در دهه 1950 میلادی مدلی از یادگیری ماشین رائه نمود، که در آن ماشین میتوانست بر حسب آموزش های قبلی خود، تصمیمات جدیدی بگیرد.
کاربرد های ماشین لرنینگ

احتمالا تهیه لیستی از جاها و کارهایی که ماشین لرنینگ در آن کاربرد ندارد راحت تر باشد! چون تقریبا در همه جا میتوانیم از ماشین لرنینگ برای بهبود عملکرد سیستم استفاده کنیم.
اما در ادامه میخواهیم به چند مورد از کاربردهای مهم ماشین لرنینگ همراه با مثال اشاره کنیم.
1- تشخیص تصویر
یکی از موارد مهمی که در ماشین لرنینگ بر روی آن کار میشود مبحث تشخیص تصویر است که کاربرد های بسیار زیادی دارد.
برای مثال در گوشی های آیفون یا برخی گوشی های شرکت های دیگر از تصویر مالک گوشی برای باز کردن قفل گوشی استفاده میشود.
یا در جاده از تشخیص تصویر برای پیدا کردن پلاک خودرو ها استفاده میشود
یا در خودرو های تسلا و خودران از پردازش تصویر برای رد کردن موانع و عبور از جاده ها استفاده میشود.
همچنین در پزشکی نیز کاربرد های بسیاری دارد برای مثال برای تشخیص تومور های سرطان در MRI
2- پردازش زبان طبیعی (Natural Language Processing - NLP)
درک زبان طبیعی نیز از کاربردهای مهم یادگیری ماشین هستش، برای مثال در دستیار های صوتی مثل Siri و Alexa از NLP برای درک دستورات کاربر استفاده میشود.
و یا برای مثال برای تبدیل گفتار به نوشتار و تمامی موضوعاتی که سعی در فهم گفتار انسان به ماشین هستند.
3- سیستم های پیشنهاد کننده (Recommendation Systems)
یکی از موضوعات داغی که شرکت های بزرگ در حال کار بر روی آن هستند سیستم های پیشنهاد کننده بر حسب علایق قبلی کاربر هست.
برای مثال شما در اینستاگرام یا فیسبوک چند پست مرتبط با موضوعی که به آن علاقه مند هستید را لایک میکنید.
وظیفه این سیستم آن است که بتواند پست ها و مطالب مشابه موضوعی که شما به آن علاقه داشتید را دوباره به شما نشان دهد.
کاری که به کرار اینستاگرام انجام میدهد، فقط کافی است شما چند پست با یک موضوع را لایک کنید، کل اکسپلور شما پر از مطالب مرتبط با آن موضوع میشود.
یا سرویس های استریم و بخش موسیقی مثل Netflix و Spotify نیز برای جذب بیشتر مخاطب از ماشین لرنینگ برای پیدا کردن موضوعات مشابه با موضوعی که کاربر به آن علاقه دارد استفاده میکنند.
چالش های ماشین لرنینگ
ماشین لرنینگ با همه ی مضایایی که دارد، چالش هایی نیز برای توسعه دهنگان و شرکت ها ایجاد میکند.
1- نیاز به داده زیاد
مدل های برای عملکرد بهتر نیاز به حجم زیادی داده برای آموزش دارند. و بدست آوردن حجم زیادی از داده کار آسانی نیست.
همچنین داده ها باید از کیفیت قابل قبولی برخوردار باشند و شامل نویز یا نقص زیادی نباشند که بتوان از آن ها برای آموزش مدل ماشین لرنینگ استفاده کرد.
2- تفسیر پاسخ دریافتی
مدل های پیچیده ماشین لرنینگ مثل شبکه های عصبی عمیق از الگوریتم های بسیار پیچیده ای استفاده میکنند برای همین تفسیر دلیل پاسخ نهایی آن ها بسیار سخت است.
برای مثال ممکن مدل ما به یک ورودی جواب غلطی بدهد، اگر بخواهیم دلیل ایراد آن را بفهمیم و مشکل را حل کنیم با مشکلات زیادی در تفسیر مدل روبرو خواهیم شد.
3- انتخاب الگوریتم مناسب
الگوریتم های زیادی برای ماشین لرنینگ وجود دارد. اما انتخاب الگوریتم مناسب برای یک وظیفه خاص آسان نیست.
و نیاز به تست و تجربه های متعدد دارد تا صحت عملکرد آن مورد آزمایش قرار گیرد.
چرا ماشین لرنینگ در چند سال اخیر پیشرفت زیادی داشته است؟

همانطور که قبل تر اشاره کردیم پیدایش ماشین لرنینگ به دهه 1950 میلادی باز میگرده اما در سال های اخیر به طرز شگفت آوری ماشین لرنینگ و هوش مصنوعی طرفدار پیدا کرده و باعث رشد این صنعت شده است.
اما چه دلایلی پشت پیشرفت سریع ماشین لرنینگ و هوش مصنوعی در چند سال اخیر است؟
1- دسترسی به حجم زیادی از داده (Big Data)
خیلی صریح میتوان گفت که ماشین لرنینگ بدون وجود داده (data) بی معنی است!
در واقع مدل ها با استفاده از حجم زیادی از داده ها میتوانند نتیجه و عملکرد خوبی داشته باشند.
برای مثال حجم داده ای که برای مدلی مشابه ChatGPT نیاز است بیش از 1000 ترابایت داده متنی است.
که این حجم از داده در گذشته وجود نداشت، اما الان با گسترش اینترنت و شبکه های اجتماعی دسترسی به این حجم از داده امکان پذیر است.
2- افزایش توان پردازشی
یکی از اصلی ترین دلایل پیشرفت در این حوزه را میتوان به افزایش توان پردازشی و قدرت محسباتی در چند سال اخیر ربط داد.
به ویژه با ظهور پردازنده های گرافیکی (GPU) و پردازنده های خاصی که برای هوش مصنوعی طراحی شده، امکان پردازش سریع تر و بهتر داده ها و اجرای الگوریتم فراهم کرده، که تاثیر بسزایی توی رشد این صنعت داشته است.
شرکت های بزرگی مثل NVIDIA در سال های اخیر با فروش سخت افزار های مناسب برای آموزش های مدل های ماشین لرنینگ پول بسیار زیادی به جیب زده اند.
این افزایش درخواست برای سخت افزار های مرتبط با یادگیری ماشین و هوش مصنوعی باعث شده که در حال حاضر (17 آبان 1403) شرکت NVIDIA با عبور از اپل تبدیل به ارزشمند ترین شرکت حال حاضر جهان شود.
3- پیشرفت در الگوریتم های یادگیری ماشین
در سال های اخیر الگوریتم های جدیدی توسعه داده شده اند که باعث شده به مدل ها کمک کنند عملکرد بهتری داشته باشند.
روش هایی مثل شبکه های عصبی عمیق، یادگیری تقویتی عمیق و مدل های انتقالی باعث بهبود عملکرد در این حوزه شده اند.
4- رایانش ابری
به زبان خیلی ساده رایانش ابری به این معنا است که شما نیازی به خرید سخت افزار قوی برای آموزش مدل های خود ندارید!
بلکه پلتفرم هایی مانند AWS (Amazon Web Service) و Microsoft Azure وجود دارند که شما با پرداخت هزینه کم میتوانید مدل های خود را بر بستر این پلتفرم ها آموزش دهید.
که این مورد باعث کاهش هزینه های یادگیری ماشین و افزایش سرعت آن شده است.
تفاوت ماشین لرنینگ و داده کاوی

برخی افراد به اشتباه فکر میکنند ماشین لرنینگ همان داده کاوی است اما این دو با هم فرق دارند.
مفهوم داده کاوی یا data mining از حدود دهه ۱۹۳۰ مطرح شد و برنامه نویس ها و شرکت ها بدنبال استخراج اطلاعات مهم از بین اطلاعات موجود داشتند.
هدف اصلی داده کاوی استخراج الگوها، روابط و اطلاعات مفید از مجموعه داده های بزرگ است. دادهکاوی بیشتر به کشف اطلاعات مفید از دادههای موجود متمرکز است.
اما در ماشین لرنینگ تلاش بر این است که با استفاده از داده های سیستمی طراحی شود که امکان پاسخ دادن به وظیفه ها و سوالاتی که قبلا با آن مواجه نشده است را داشته باشد.
انواع روش های ماشین لرنینگ

یادگیری ماشین را میتوان به 3 دسته کلی تقسیم کرد.
1- یادگیری نظارت شده (Supervised Learning)
در این روش مدل با داده های برچسب زده شده (Labeled) آموزش میبیند.
داده های برچسب دار به ما کمک میکنند که بتوانیم خروجی داده های جدید را تشخیص بدهیم. همانطور که از اسم آن هم مشخص است این روش با حضور یک ناظر انجام میشود.
برای مثال ما میخواهیم سیستمی را پیاده کنیم که قادر به تشخیص وجود یک حیوان در عکس باشد.
ابتدا باید تعدادی داده برچسب دار (یعنی مشخص بشه چه حیوانی تو عکس هست) را آماده کنیم که بتوانیم با این داده ها مدل را آموزش بدهیم.
بعد این داده ها را به یک الگوریتم نظارت شده میدهیم که بتواند روابط بین داده ها و برچسب ها را کشف کند.
بعد از آموزش مدل میتوانیم با داده های جدیدی آن را تست کنیم که متوجه بشویم تا چه حدی درست کار میکند
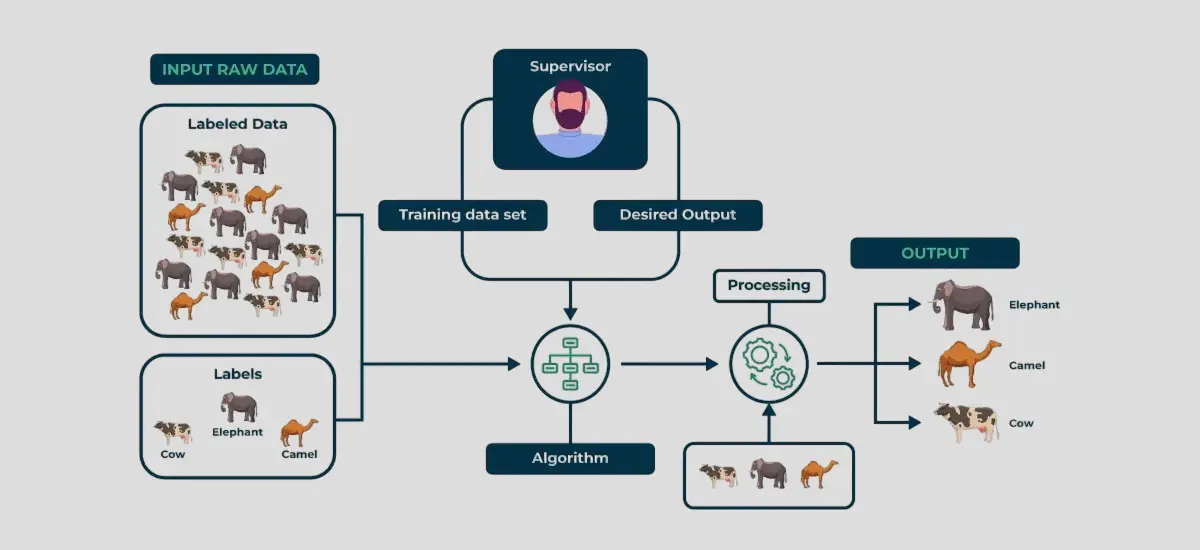
حال میخواهیم در مورد انواع روش های یادگیری نظارت شده صحبت کنیم
دسته بندی یا Classification
این روش موقعی استفاده میشود که داده ها را به توان به چند دسته تقسیم کرد یا در واقع داده ها بصورت گسسته باشند.
برای مثال داده ها true یا false باشند. یا شکست و پیروزی یا اسپم بودن و اسپم نبودن یک ایمیل ...
در این صورت چون میتوانیم داده ها را دسته های جدا و مشخص تقسیم کنیم پس در دسته Classification قرار میگیرد
رگرسیون یا Regression
در این حالت داده های بصورت پیوسته هستند و امکان دقیق مشخص کردن چند دسته بندی را نداریم.
برای مثال میزان حقوق برنامه نویسان iOS در ایران را نمیتوانیم به چند دسته خاص تقسیم کنیم. بلکه جواب بصورت پیوسته است.
2- یادگیری بدون نظارت (Unsupervised Learning)
در یادگیری بدون نظارت داده ها بدون برچسب به مدل داده میشوند. این الگوریتم بدون نیاز به دخالت عامل خارجی (انسان) میتواند الگو های مختلف و پنهان میان داده ها را تشخیص دهد.
این روش معمولاً در مواقعی استفاده میشود که دادههای label خورده در دسترس نیست یا label گذاری آن ها هزینه بر است. و نکته ای که باید به آن توجه کرد این است که یادگیری نظارت شده از دقت بالاتری برخوردار است اما حتما نیاز به داده های برچسب دار است.
اکثرا مواقعی از یادگیری بدون نظارت استفاده میکنیم که به داده های برچسب دار دسترسی نداشته باشیم.
برای مثال در بازاریابی، شرکت ها از یادگیری بدون نظارت برای خوشهبندی (clustering) مشتریان استفاده میکنند.
مدل میتواند مشتریان را بر اساس رفتار خرید، علاقهمندی ها، اطلاعات شبکه های اجتماعی و ... به چند گروه تقسیم کنند.این کار میتواند منجر به تعیین استراتژی های بازاریابی به صورت هدفمند برای هر گروه شود.
3- یادگیری تقویتی (Reinforcement Learning)
یادگیری تقویتی روشی است که در آن یک عامل (agent) از طریق تعامل با محیط خود و با دریافت پاداش (reward) یا تنبیه (penalty) یاد میگیرد.
این مدل ها از طریق آزمون و خطا (Trial and Error) یاد می گیرند چگونه در یک محیط عمل کنند تا پاداش بهینه (Optimal Reward) کسب کنند.
این روش بیشتر در شرایطی استفاده میشود که مدل باید به طور پیوسته تصمیم گیری کند و اقدامات آن بر اساس بازخوردی که از محیط دریافت میکند تنظیم میشود.
حال میخواهیم ویژگی های اصلی یادگیری تقویتی را بیان کنیم.
- تعامل عامل با محیط: عامل از طریق اقدامات خود بر محیط تأثیر می گذارد و بازخورد دریافت می کند.
- پاداش و جریمه: سیستم بر اساس عملکرد عامل، پاداش یا تنبیه ارائه میدهد.
نمونه معروفی از عملکرد یادگیری تقویتی را میتوانیم در بازی هایی مثل شطرنج یا Dota 2 ببینیم که با آموزش سیستم میتوانیم رقیب های انسانی را شکست دهیم.
ماشین لرنینگ در iOS و Swift

یکی از تصورات اشتباهی که برخی از برنامه نویسان دارند این است که فکر میکنند ماشین لرنینگ محدود به زبان پایتون است.
البته که پایتون اگر بهترین زبان برای ماشین لرنینگ نباشد، قطعا جزو بهترین ها هست! اما این به آن معنا نیست که برنامه نویسی ماشین لرنینگ فقط محدود به پایتون میشود.
ما در زبانی مثل سوئیفت نیز امکان کار بر روی ماشین لرنینگ را داریم.
برای این منظور از framework ای که اپل برای این منظور توسعه داده، یعنی CoreML میتوانیم استفاده کنیم.
کاربرد های CoreML
حال میتوانیم بخشی از کاربرد های CoreML را بیان کنیم.
- تشخیص تصاویر: شناسایی اشیا یا افراد در تصاویر
- پردازش زبان طبیعی (NLP): تحلیل متن و ترجمه
- تشخیص صدا: شناسایی کلمات
اگر دوست دارید که با CoreML و برنامه نویسی iOS آشنا شوید، لینک زیر را مشاهده کنید:

ماشین لرنینگ تا کجا میتواند پیش برود؟

شاید فیلم هایی مثل Subservience را دیده باشید که ربات هایی وجود دارند که تقریبا به طور کامل میتوانند کار هایی که انسان میکند را انجام دهند.
صحبت در این باره بسیار سخت است و شاید یجورایی پیش بینی آن غیر ممکن باشد.
برخی در این بین ادعا میکنند که ماشین لرنینگ و هوش مصنوعی در نهایت میتوانن جای بسیاری از انسان ها و برنامه نویس ها را بگیرند.
برخی دیگر هم معتقد هستند که هیچ وقت نمیتواند جای انسان را پر کند.
اما چیزی که بنده فکر میکنم این است که در حال حاضر ابزار های هوش مصنوعی و ماشین لرنینگ تا حدی زیادی به کمک انسان ها آمده اند و جای انسان ها را پر نکرده اند. اما در آینده احتمالا بتوانند جای برخی از افراد غیر متخصص را پر کنند.
اما پیش بینی آینده دور واقعا غیر ممکن است...
